Mastering DARWIN EU 2.0 Interoperability for JCA Compliance:
The Technical Blueprint for Multi-State Real-World Evidence

The European market access landscape is undergoing its most profound structural disruption since the centralization of regulatory approvals. The rollout of the European Union Health Technology Assessment (EU-HTA) regulation has effectively shifted the goalposts for pharmaceutical manufacturers. No longer can global launch teams rely solely on randomized controlled trials (RCTs) supplemented by localized, retrospective registry data to clear pricing and reimbursement hurdles.
At the center of this paradigm shift are two highly technical, codependent pillars: the Joint Clinical Assessment (JCA) process, driven by the granular demands of the PICO (Population, Intervention, Comparator, Outcome) framework, and the European Medicines Agency’s (EMA) rapidly expanding DARWIN EU 2.0 (Data Analysis and Real World Interrogation Network) infrastructure.
For Market Access VPs, Health Economics and Outcomes Research (HEOR) Directors, and Real-World Evidence (RWE) Scientists, the core challenge of 2026 is no longer conceptual; it is operational. The industry is facing a critical execution bottleneck: How do we achieve seamless multi-state data interoperability and deploy robust real-world data (RWD) bias mitigation strategies that withstand the automated, federated scrutiny of European HTA bodies?
If your evidence generation framework cannot withstand this algorithmic validation, your product launch faces an immediate regulatory lockout across multiple member states. This comprehensive guide details the technical requirements, software architectures, and strategic methodologies required to achieve DARWIN EU 2.0 interoperability for JCA compliance.
1. The Operational Reality of DARWIN EU 2.0 and the JCA Bottleneck
The transition to DARWIN EU 2.0 introduces a federated network architecture designed to perform rapid, multi-state database interrogations. Operating on a decentralized model, DARWIN EU utilizes the OMOP (Observational Medical Outcomes Partnership) Common Data Model (CDM) to standardize electronic health records (EHRs), insurance claims, and disease registries across diverse healthcare systems throughout Europe.
The Interoperability Friction Point
When a pharmaceutical manufacturer submits a JCA dossier, European HTA assessors utilize the DARWIN EU network to independently validate, challenge, or supplement the manufacturer’s clinical assertions. This creates an immediate evidentiary friction point. If the manufacturer’s proprietary RWD packages are derived from siloed, non-OMOP mapped databases, a significant data-translation gap occurs.
Reference: Darwin EU Data Interoperability
Multi-state data interoperability requires more than mere semantic alignment; it demands syntactic and structural uniformity. Differences in national clinical coding systems, such as ICD-10-GM in Germany vs. read codes or SNOMED-CT in other jurisdictions, frequently lead to critical telemetry loss during evidence synthesis. When data fields lose fidelity across borders, the statistical power of the evidence package degrades, triggering immediate pushback from JCA assessors regarding data integrity.
The PICO Proliferation Crisis
Under the EU-HTA mandate, manufacturers do not face a single, unified comparator framework. Instead, member states submit their localized medical requirements, which the JCA coordination group synthesizes into multiple distinct PICO questionnaires. A single product launch can face upward of 15 to 20 divergent PICO requirements, each demanding specific comparator rationales, sub-population segmentations, and localized real-world outcomes.
To satisfy these multidimensional queries simultaneously, your RWE pipeline must transition into an agile, programmatic engine. Manual evidence generation, relying on classic retrospective database queries that take 6 to 12 months to execute, is fundamentally incompatible with the tight JCA submission windows.
2. Technical Architecture for Multi-State Data Interoperability
To bridge the gap between fragmented European health networks and the centralized JCA process, market access teams must adopt a standardized data engineering pipeline. Achieving DARWIN EU 2.0 interoperability requires a three-tier technical framework rooted in the OMOP CDM.
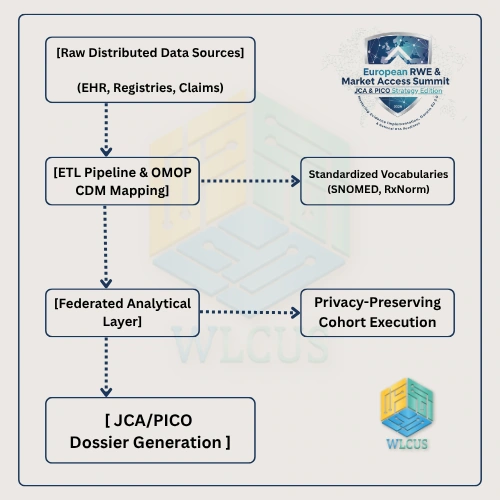
Step 1: Semantic Harmonization via ETL Protocols
The transformation of disparate distributed data networks into decision-grade real-world evidence begins with a highly disciplined Extract, Transform, Load (ETL) protocol. Teams must establish automated semantic mapping pipelines that convert localized medical charts into standardized clinical vocabularies:
Conditions: Mapped entirely to SNOMED-CT.
Medications: Harmonized through RxNorm or the ATC (Anatomical Therapeutic Chemical) classification system.
Procedures: Unified via CPT-4 or localized national equivalents cross-referenced with standardized OMOP procedure concepts.
Step 2: Implementing Privacy-Preserving Federated Analytics
Because the European General Data Protection Regulation (GDPR) severely restricts the cross-border transfer of raw patient-level data, data engineering teams must implement privacy-preserving federated analytics. Rather than pooling raw data into a centralized repository, manufacturers must deploy containerized analytical scripts (e.g., Docker containers running R or Python-based cohort definitions) directly to localized data nodes across individual member states.
This architecture ensures that only aggregated, completely anonymized statistical summaries are extracted and combined. This matches the exact method utilized by the DARWIN EU coordination center, ensuring that the manufacturer’s evidence-generation engine operates symmetrically with the regulators’ auditing tools.
3. Advanced RWD Bias Mitigation Strategies for Regulatory Scrutiny
Even with perfect data interoperability, real-world data is inherently vulnerable to systemic confounding, selection bias, and information gaps. Under the scrutiny of JCA reviewers, unmitigated bias is categorized as missing or low-quality evidence, which directly weakens value communication during national pricing negotiations.
To convert raw clinical data into regulatory-grade evidence, biostatisticians and evidence synthesists must embed three core statistical frameworks directly into their analytical pipelines.
Framework A: High-Dimensional Propensity Score (hdPS) Matching
Traditional propensity score matching models rely on investigator-selected covariates, which are highly vulnerable to human bias and overlooked confounders. For JCA submissions, teams must deploy high-dimensional propensity score (hdPS) algorithms.
The hdPS framework automatically scans thousands of codes across multiple data dimensions (diagnoses, procedures, drug dispensations) to identify and prioritize proxy variables for unmeasured confounders. This mathematical rigor drastically reduces confounding by indication, a primary point of criticism during HTA evaluations.
Framework B: Quantitative Bias Analysis (QBA)
JCA assessors frequently challenge the robustness of RWD when certain confounding variables are completely unobserved within an EHR or registry database (e.g., smoking status, body mass index, or baseline functional scores). Instead of presenting these missing elements as a limitation, manufacturers must proactively run Quantitative Bias Analysis (QBA).
By applying probabilistic or deterministic QBA modeling, teams can mathematically simulate how strong an unmeasured confounder would need to be to invalidate the observed treatment effect. Demonstrating that an unobserved variable has negligible statistical power to alter the clinical outcome provides a definitive defense during rigorous evidence reviews.
Framework C: External Control Arm (ECA) Validation
For rare diseases and targeted precision oncology pathways where a randomized control group is ethically or logistically unfeasible, External Control Arms (ECAs) built from historic or concurrent RWD are essential. However, to pass JCA validation, the ECA must be constructed using strict structural emulation principles:
Target Trial Emulation (TTE): Design the protocol of the observational RWD study to precisely mirror the inclusion, exclusion, and randomization timelines of the active clinical trial arm.
Zero-Time Index Alignment: Ensure that time-zero (index date) is synchronized perfectly between the trial participants and the real-world external cohort to completely eliminate immortal time bias.
4. The Toolkits: Statistical Software and Machine Learning Frameworks
Moving from manual data analysis to automated, compliant pipeline execution requires a modern stack of statistical software and machine learning infrastructure. The standard tools transforming modern market access operations include:
OHDSI WebAPI & HADES Packages
The OHDSI (Observational Health Data Sciences and Informatics) network provides an open-source suite of tools known as HADES (Health Analytics Data to Evidence Suite). Built entirely in R, these packages are specifically optimized for running large-scale, multi-state analyses on OMOP CDM databases.
CohortMethod: Utilizes advanced large-scale propensity score matching and Cox proportional hazards regression to perform comparative effectiveness research.
MethodEvaluation: Automatically quantifies the operational predictive validity of specific study designs against a particular data infrastructure.
Clinical Natural Language Processing (cNLP) Engines
Up to 80% of critical clinical evidence in oncology and rare diseases lives within unstructured data formats, such as doctor’s consultation notes, pathology reports, and radiology narratives. Standard ETL pipelines miss these elements completely.

To extract this data, advanced evidence engines deploy fine-tuned transformer models running Clinical NLP (cNLP). These engines run named entity recognition (NER) and relation extraction algorithms to accurately capture deep phenotypic variables, such as:
Specific gene mutations and biomarker status changes over time.
Granular tumor progression timelines and ECOG performance scores.
Unstructured patient-reported adverse events.
By structuring these qualitative variables and integrating them directly into the standard OMOP data schemas, manufacturers can construct highly specific PICO target profiles that traditional coding frameworks miss entirely.
5. Driving Organizational Agility: Aligning Cross-Functional Teams
Solving the PICO crisis is not merely a technical challenge, it is a profound operational and organizational hurdle. Historically, pharmaceutical companies have run their departments as independent, sequential siloes:
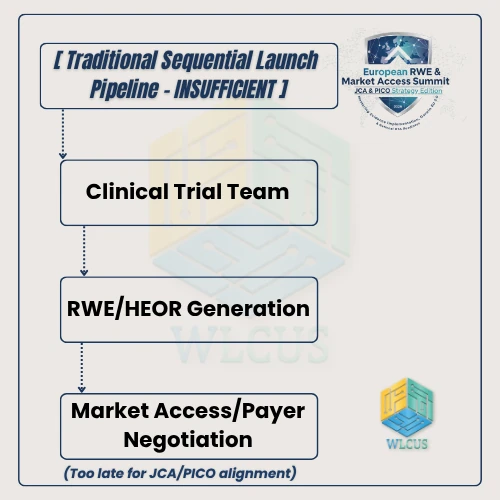
In the DARWIN EU 2.0 era, this linear approach introduces severe commercial risk. If the clinical trial team selects comparators without analyzing the real-world multi-state data landscapes, the market access team will receive a JCA dossier that is fundamentally unaligned with local PICO mandates.
Implementing the Integrated Launch Sequence
To survive in this new regulatory environment, companies must build a cross-functional, agile data engine that operates concurrently across the entire product lifecycle:
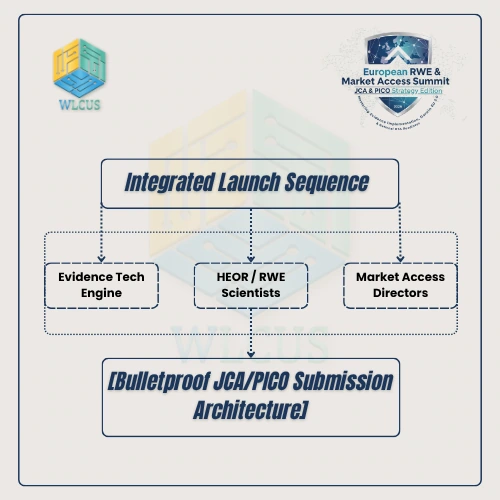
Evidence Technology Leads: Deploy the underlying OMOP data engines, cNLP extractors, and automated data processing tools early in Phase II development.
RWE & HEOR Scientists: Build dynamic analytical models that simulate various PICO scenarios long before the clinical trial readouts occur.
Market Access Directors: Continuously feed real-time payer intelligence and localized HTA requirements directly back into the evidence generation pipeline.
By uniting these three distinct skill sets under a single operational objective, manufacturers ensure that their evidence package is naturally tailored for JCA compliance from day one.
6. Case Study: Mitigating Selection Bias in an Oncology Multi-State Data Package
To fully appreciate the real-world impact of these integrated frameworks, consider the following technical architecture deployed during a recent high-stakes oncology submission across three separate European healthcare jurisdictions (Germany, France, and the Netherlands).
- The Challenge
The manufacturer needed to demonstrate the comparative effectiveness of a novel precision medicine targeting a niche genetic biomarker against standard-of-care chemotherapy. The active clinical trial was single-arm due to the rarity of the mutation, necessitating a robust External Control Arm (ECA) drawn from real-world registry and electronic health record databases across the three target countries.
The primary hurdle was extreme selection bias and missing data: the biomarker of interest was only systematically tested in recent medical history, and clinical documentation practices varied significantly across the target countries’ data systems.
- The Solution Design
- Data Harmonization via OMOP CDM: The local databases in each country were mapped into the OMOP Common Data Model format. A specialized Clinical NLP (cNLP) model was deployed across the unstructured oncology narratives to extract retrospective biomarker test results, tumor response measurements, and ECOG performance statuses that were missing from structured billing logs.
- Target Trial Emulation Protocol: To align the cohorts, investigators established a strict time-zero protocol. Real-world patients were index-dated precisely at the initiation of first-line standard chemotherapy, matching the clinical trial eligibility criteria to avoid immortal time bias.
- High-Dimensional Propensity Score (hdPS) Balancing: Over 1,200 automatically extracted variables, ranging from concurrent medication history to detailed diagnostic codes, were evaluated by an hdPS algorithm to calculate individual propensity scores. Patients in the ECA were then matched 1:4 with the trial population using variable optimal matching.
- Sensitivity Testing with QBA: To address unmeasured confounding regarding historic smoking status (which was missing in 35% of the Dutch registry charts), biostatisticians completed a probabilistic Quantitative Bias Analysis. The simulation mathematically proved that even if smoking prevalence was heavily imbalanced between the arms, the relative risk estimate would shift by less than 5%, preserving the statistical significance of the primary outcome.
By presenting a fully harmonized, bias-mitigated multi-state evidence package that directly emulated the required PICO comparator parameters, the manufacturer bypassed standard technical objections from JCA assessors. The evidence was validated as high-quality, laying a secure baseline for subsequent value communication and pricing success at the individual member-state level.
The Access Outcome
By presenting a fully harmonized, bias-mitigated multi-state evidence package that directly emulated the required PICO comparator parameters, the manufacturer bypassed standard technical objections from JCA assessors. The evidence was validated as high-quality, laying a secure baseline for subsequent value communication and pricing success at the individual member-state level.
Conclusion: Securing the New Standard of Market Access
The era of navigating European market access through disconnected, localized dossiers is gone. The introduction of DARWIN EU 2.0 and the rigid structural enforcement of the JCA PICO framework require an uncompromising, highly technical approach to real-world evidence generation. Manufacturers can no longer look at data interoperability or advanced bias mitigation as optional research exercises, they are foundational blueprints for commercial survival.
Unlocking these complex pathways requires an ongoing commitment to data science excellence, cross-functional agility, and deep regulatory alignment. To win the launch sequence in 2026 and beyond, your evidence generation pipelines must be as advanced, standardized, and precise as the clinical therapeutics you bring to market.
The technical blueprints outlined in this document represent the fundamental baseline for modern product launches. However, translating these frameworks into immediate corporate success requires direct access to operational case studies, masterclasses, and peer-to-peer strategic collaboration.
To bridge the gap between regulatory theory and real-world clinical implementation, join the elite assembly of pharmaceutical executives, evidence scientists, and access leaders at the 2nd Annual European RWE & Market Access Summit 2026, held live in Amsterdam on October 21-22.
Our dedicated JCA & PICO Strategy Edition program completely bypasses academic generalities to focus on the concrete mechanics of high-stakes market access:
Live Case Study Breakdowns: Gain direct exposure to active pharmaceutical submissions highlighting explicit PICO definitions, advanced bias mitigation strategies, and the statistical software utilized to clear JCA hurdles.
DARWIN EU 2.0 Technical Briefings: Interact directly with HTA strategists and data platform innovators breaking down the latest technical expectations for multi-state data interoperability and federated analytics.
Cross-Functional Launch Frameworks: Master the operational toolkits required to perfectly synchronize your RWE, HEOR, Pricing, and Medical Affairs teams for accelerated access pathways.
Do not let your 2026-2028 launch pipeline be caught unprepared by the evolving EU-HTA landscape. Secure your organization’s competitive advantage, protect your multi-million dollar clinical investments, and claim your seat among the leadership community defining the future of global healthcare evidence implementation.